


Fine‑Tuning AI Sinks Budgets Faster Than You Think
Ground answers in your live documents first—then decide if weight surgery is worth the extra time and money.

Fine-tuning is the step that most teams skip the moment someone says, "We need the model to know our business." Everyone from vendor webinars to conference keynotes frames it as "step two" once you've chosen a foundation model, so teams dive in almost by reflex.
But as soon as the scope hits a project plan, the reflex shows its cracks: timelines swell, labeling work crowds out feature work, and your freshest knowledge sits in yet‑to‑be‑processed files.
Before you commit to surgery on the model itself, pause. There's a simpler way to ground answers in what you know right now—retrieval‑augmented generation. To understand why this difference matters, let's start with the costs of fine-tuning.
The hidden cost behind fine‑tuning
Most teams hit "fine‑tune" the moment a foundation model needs domain depth, assuming it's a one-time tax they can amortize over time. The reflex feels safe until the second invoice lands.
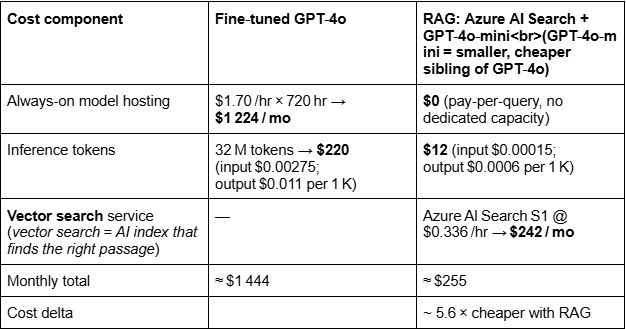
Hidden math
Scenario: 10‑seat support bot · ≈ 40 000 queries/month (≈ 200 questions per agent per week) · 400 input + 400 output tokens per query
What you can do
Do a 3‑step napkin check:
Token budget: monthly queries × 800 tokens ≈ total tokens.
Fine‑tune cost: (tokens × $0.014) + $1.70 × 720 hrs.
RAG cost: (tokens × $0.00075) + AI Search S1 $0.34 × 720 hrs.
If RAG isn’t at least 4 times cheaper, jump to Section 5; your use case may be a fine-tune exception.
Accuracy on the long tail, where fine-tuning falls flat
Teams often fine‑tune, believing it "locks in" proprietary knowledge and reduces hallucinations.
A 2024 SIGIR benchmark shows that retrieval-augmented generation "surpasses fine‑tuning by a large margin" on the least popular facts, precisely the edge-case queries that trigger compliance or CX failures. In the same study, fine-tuned models returned an incorrect or ungrounded answer 38% of the time when asked about low-frequency entities; RAG reduced that to 8%.
Case on point
A regional clinic (≈ 600 beds, $200 M annual turnover) piloted a RAG‑powered policy assistant after repeated HIPAA‑review delays on its fine-tuning plan.
With RAG, the bot cited the exact policy clause in every response, reducing nurse lookup time by 42 seconds per query and clearing internal audits within two weeks.
What you can do
Run a groundedness test:
Collect 25 rarely asked but high‑stakes questions (audit, policy, rare SKUs).
Ask your current model to answer and self‑grade: Is every answer citing a source passage?
≥ 90 % grounded → you're safe for now.
< 90 % grounded → Stand up a simple RAG prototype before investing another sprint in fine‑tuning.
Time‑to‑value: from idea to production in < 30 days
Fine-tuning is penciled in as “one extra sprint.” In practice, it becomes three: data prep, training, and compliance re‑approval, easily stretching launch dates into the next quarter.
A RAG pipeline skips weight surgery, so shipping is measured in weeks. DoorDash’s voice-support assistant went live in just 8 weeks, cutting development time by 50% compared to its fine-tuning plan.
Microsoft’s own Bot Framework case studies echo the pattern: 30% faster deployment when RAG is paired with Azure Cognitive Search.
That speed flips AI from capital project to in-year ROI: the sooner the bot answers real customers, the sooner savings or upsell revenue hit the P&L without waiting for the next budget cycle.
What you can do
Pick one low‑stakes corpus (e.g., HR policies or product FAQs) and set a 30‑day clock: ingest, index, and connect to an off‑the‑shelf model.
If you can’t demo live answers within a month, the workload may require fine-tuning or a rethink.
Compliance & audit lens
Regulators and internal risk teams now require more than accuracy. They want to see the source of every automated answer. A fine‑tuned model can’t cite a paragraph; its knowledge is baked invisibly into 70 billion parameters.
Retrieval‑augmented generation returns the passage that justified its response, so auditors jump straight from the chat transcript to the source doc.
Both Morgan Stanley’s wealth‑advice bot and Mayo Clinic’s clinician assistant chose RAG for that reason: every reply is anchored to a policy PDF or medical guideline.
In the Mayo pilot, compliance staff reduced document-tracing time from 90 minutes to 10 minutes per flagged answer because evidence was one click away rather than requiring a manual search. Multiply that by hundreds of annual spot checks, and the labor delta alone pays for the vector‑search bill.
What you can do
List the knowledge bases that must survive an external audit (e.g., claims handling, clinical protocols, ISO‑controlled SOPs).
Prioritize RAG for those first; its built‑in citations will shave days off your next compliance review.
When focused, fine-tuning still beats RAG
Retrieval pipelines solve most problems but not everyone. A few edge conditions still tip the balance back toward tuning the model itself.
Latency is the first red flag: every retrieval hop adds a network round-trip, and field tests show that RAG answers can run 30–50% slower than a single-pass tuned model. The picture gets starker when the application must run offline or on tight hardware.
Google’s Gemma 3n, a 3‑billion‑parameter model that answers locally in under 30 milliseconds on a 2 GB device, exists precisely because some workloads have no place for an external index .
Compliance can be another blocker: if documents may never leave a secure enclave, embedding them for retrieval is off‑limits.
Finally, token‑dense reasoning, thinking of long legal clauses or step‑by‑step math, still skews in favor of fine‑tunes that were trained for the job.
Teams that meet two or more of these constraints often adopt parameter-efficient fine-tuning (PEFT). By training just 1–2% of the weights, PEFT reduces compute time by up to 90% compared to a full fine-tune while preserving the low-latency offline benefits.
Forcing RAG into these corners risks customer-visible lag, data policy violations, or sudden GPU bills when numeric prompts balloon. Selecting the right pattern helps maintain performance and compliance budgets.
What you can do
Gut-check your next use case: if you must hit a sub-50 ms p95, operate offline, or keep documents locked in one enclave, prototype a small PEFT adapter first—RAG can wait for the next workload.
Fine‑tuning locks knowledge into expensive weights; retrieval keeps it alive at a fifth of the cost.
Want to see those savings on your data? Book our Gen AI POC Implementation on Azure Marketplace. We’ll set up a RAG-based proof of concept, complete with cost and latency analysis, so that you can assess ROI before a full rollout.