


Open-source AI vs ChatGPT and Bard
Ever considered using Open-source AI models? Here's why you might want to use them.

Linux, Python, and WordPress are some popular open-source projects that you might’ve worked on or used. And there are many more which have greatly benefited the community.
With the Gen AI revolution in full swing, it’s natural to ponder how open-source initiatives will shape this trend.
Will open-source become the foundation of a popular AI tool used by the masses? Or will it be confined to just some enthusiasts?
Who knows.
In this edition though, I intend to explore the open-source side of Gen AI. We’ll cover:
10 Best Open-Source LLMs You Should Know
Will Open-Source Models End Google and OpenAI?
Code Llama: An Open-source Model for Coding
10 Best Open-source LLMs You Should Know
1. GPT-NeoX-20B: Developed by EleutherAI, this open-source LLM has 20 billion parameters and is trained on the Pile dataset. It demonstrates efficient multi-GPU training and boasts enhanced contextual understanding with multilingual proficiency.
2. GPT-J: Also created by EleutherAI, GPT-J has 6 billion parameters and is based on the GPT-2 architecture. It provides powerful text generation, few-shot learning capability, and is easy to use.
3. LLaMA 2: Developed by Meta AI and Microsoft, this advanced multimodal LLM can comprehend and generate text while understanding images. It features enhanced contextual understanding, adaptive communication, and ethical and responsible AI.
4. OPT-175B: Meta AI's Open Pre-trained Transformer model has 175 billion parameters and is trained on English text data. It uses gradient checkpointing, supports mixed precision training, and enables reduced carbon footprint in AI development.
5. BLOOM: Developed by BigScience, BLOOM is a large-scale, open-access, multilingual language model aimed at fostering scientific collaboration. It has 176 billion parameters and relies on 46 natural world languages and 13 programming languages.
6. Baichuan-13B: Baichuan Inc. unveiled this open-source LLM with 13 billion parameters tailored for both English and Chinese AI language processing and generation. Its applications include text generation, summarization, and translation.
7. CodeGen: Created by researchers at Salesforce AI Research, CodeGen offers several sizes from 350 million to 16 billion parameters. It's ideal for code generation, language flexibility, and error handling.
8. BERT: Developed by Google AI, BERT has up to 340 million parameters and uses bidirectional context understanding. It incorporates attention mechanisms and masked language models for enhanced language comprehension.
9. T5: Google AI's T5 is a versatile pre-trained language model based on the Transformer architecture, designed to handle various NLP tasks. Boasting 11 different sizes, its largest model contains 11 billion parameters.
10. Falcon-40B: A large language model trained to predict the next word in a sequence, Falcon-40B showcases potential for revolutionizing various NLP tasks with its advanced language comprehension and autoregressive decoder-only model.
Some other notable mentions are Vicuna-33B, MPT-30B, Dolly 2.0, Platypus 2.0, and Stable Beluga 2.
To dive deeper into the key features and other details of these open-source LLMs, you may click here.
Open-Source Models Will End Google and OpenAI, Says Leaked Google Document
In May 2023, a leaked Google document created quite a buzz in the AI space.
It predicted the end of Google and OpenAI at the hands of open-source AI models. And the document had some valid arguments backing the claim.
It cited the recent AI breakthroughs made by individuals and small businesses using open-source models.

It also mentioned how smaller, cheaper open-source language models are quickly catching up and stirring up the competition.

The author of this leaked document says the enterprise approach of retraining language models from scratch isn’t effective.

They expressed concern about how the time and cost-consuming large models from companies like Google and OpenAI put them in a disadvantageous position compared to open-source models.

In the end, the doc urged decision-makers at Google to collaborate with open-source contributors to win the AI race.
The AI revolution is still in its infancy. And it’s too early to call out a winner. However, the doc clearly highlights open-source AI models can be extremely useful for small businesses and ventures.
So, the right strategy for businesses might be to experiment with open-source models on the side. Established AI models like GPT and Bard could power the AI features until something worthwhile comes out of open-source experiments.
I covered the above event in detail in my other newsletter. You may check out that edition here.
Code Llama: An Open-Source Model for Coding
Meta is leading the dance when it comes to open-source AI initiatives among established enterprises. They launched Code Llama earlier this year, and it’s impressive.
Code Llama is a code-specialized large language model (LLM) built on top of Llama 2. It was created by further training Llama 2 on code-specific datasets for a longer duration. The model is designed to generate code, provide code completion, and help in debugging. It supports popular programming languages such as Python, C++, Java, PHP, Typescript, C#, and Bash.
Three sizes of Code Llama have been released: 7B, 13B, and 34B parameter models, each catering to different serving and latency requirements. Additionally, specialized variations like Code Llama - Python and Code Llama - Instruct have been developed for more targeted usage:
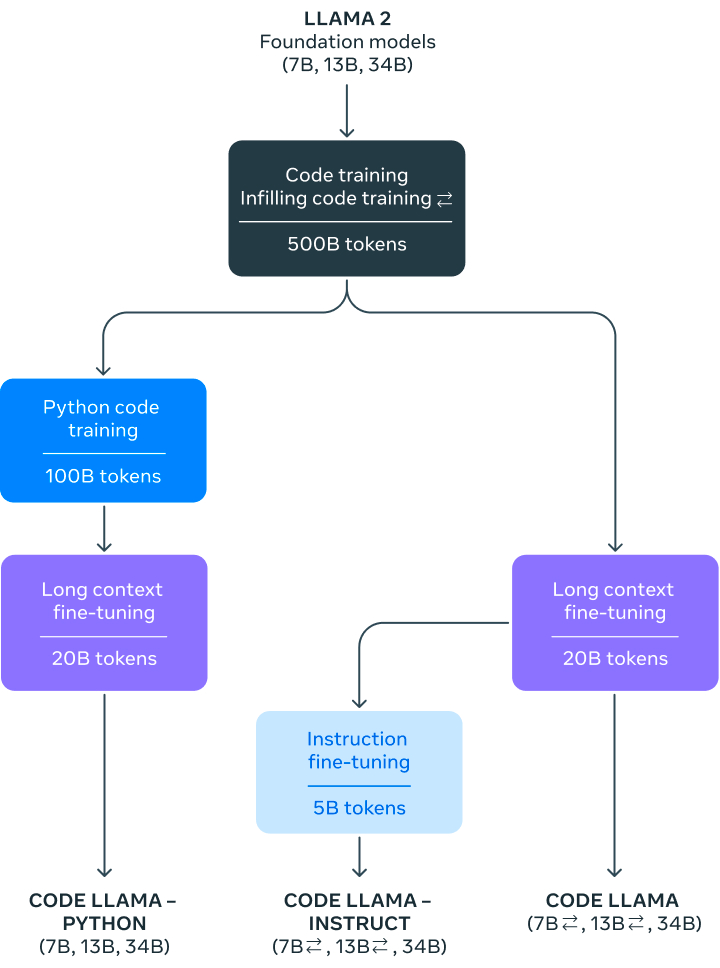
1. Code Llama - Python: This is a language-specialized variation, further fine-tuned on 100B tokens of Python code. It targets Python, which is the most benchmarked language for code generation and holds an essential role in the AI community, making it a valuable specialization.
2. Code Llama - Instruct: This variation is instruction fine-tuned and aligned to work better with natural language instructions. It is fed with natural language input and the expected output to better understand and generate helpful, safe, and expected outputs from user prompts. For code generation purposes, it is recommended to use Code Llama - Instruct variants.
Code Llama has various use cases, including:
1. Generating code from natural language prompts.
2. Code completion by inserting code into existing code.
3. Debugging scenarios in larger codebases.
4. Providing context-aware code suggestions.
To evaluate Code Llama, the models were tested using two popular coding benchmarks: HumanEval and Mostly Basic Python Programming (MBPP). In these tests, Code Llama outperformed open-source code-specific LLMs and surpassed the performance of Llama 2.

As a part of the evaluation process, red teaming efforts were undertaken to assess risks associated with generating malicious code. Quantitative evaluations were conducted, and Code Llama provided safer responses compared to ChatGPT (GPT3.5 Turbo).
You can read more about Code Llama here.