


How Dropbox Orchestrates 30M Tasks/Min Through A Unified Model
When processing millions of tasks across specialized systems became unsustainable, Dropbox rethought their approach to infrastructure management just by applying first principles.

Growth in tech is deceptive.
You see, performance maintenance is easy when the user base is small and features are limited. What happens when your platform needs to handle millions of background operations every minute - from file uploads to security checks to search indexing?
The architecture that powers your success eventually becomes your biggest constraint. Your systems still work. Your teams still ship. But under the surface, everything is slowly but constantly crumbling.
Dropbox's recent infrastructure evolution is a great example of how to get out of this complexity trap by taking a step back and rethinking how different parts of your systems communicate and process tasks.
Over the past couple of years, their original asynchronous infrastructure, designed for basic file operations, suddenly needed to handle AI features, coordinate hundreds of product workflows, and process over 30 million background tasks every minute.
So, they deconstructed the entire async infrastructure and built the Messaging System Model (MSM), a five-layer architecture.
Read on to know the exact challenges they faced, how it all began, and the solution they devised to get back to smooth system performance.
How their async system started struggling
Dropbox's infrastructure had grown into multiple disconnected async systems, each built for specific product needs - from streaming file upload events to powering security, abuse prevention, machine learning, and search indexing.
Processing over 30 Billion requests daily to dispatch jobs, they knew that adding more senior engineers wasn't going to solve their fundamental problems.
- Developer velocity kept dropping. Engineers spent more time learning multiple complex systems and handling operational tasks than building product features.
- Reliability became a serious concern. Performance was inconsistent and unpredictable, with different services having varied SLOs for availability, latency, and processing.
The systems weren't multi-homed either. This created major reliability risks if a data center failed.
- Infrastructure hit scaling limits. Components like their delayed event scheduler had already reached maximum throughput capacity.
This forced them to implement rigorous screening for each new use case, which is not ideal when you're trying to innovate rapidly..
- Extensibility became nearly impossible. The existing systems couldn't adapt to product demands, especially with their new filesystem architecture, which required Cypress to distribute events to multiple subscribers within Dropbox.
These problems were holding back Dropbox's ability to build and ship new features quickly enough.
So, how did they solve these challenges?
The team at Dropbox took the time to clearly define their goals first, which truly is the single-most deciding factor of any engineering initiative before it even begins. Their top three priorities were improving developer velocity, creating a robust async foundation, and optimizing operational efficiency.
They realized they couldn't demolish everything and start fresh - not with 400 business workflows depending on these systems. They needed an approach that would let them improve the system piece by piece.
Drawing inspiration from the OSI network model, they developed a messaging system model (MSM) with five distinct layers:
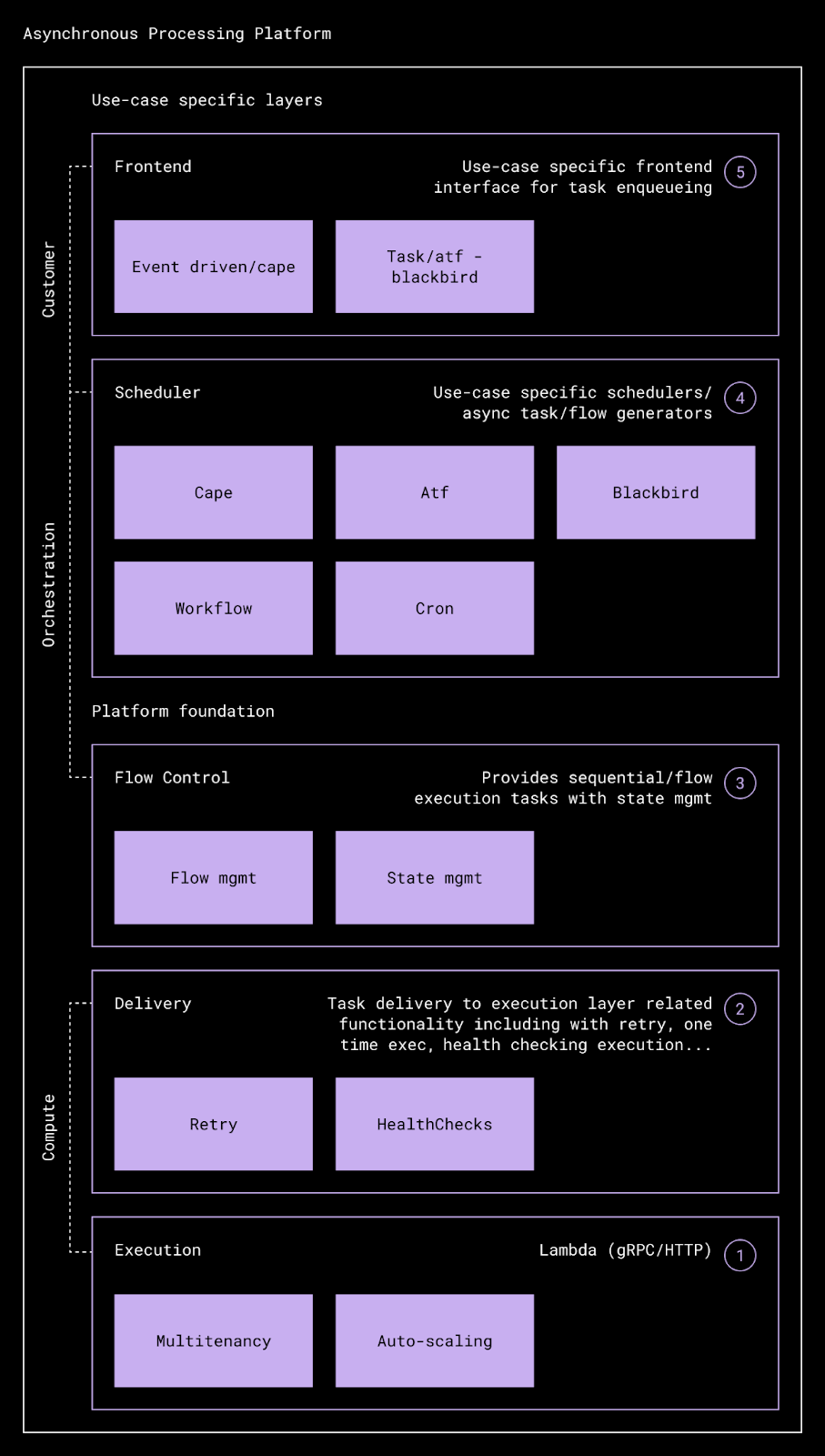
(An illustration of the five components of the Messaging System Model)
The Frontend layer is the entry point where both engineers and systems publish their events. It validates every event's schema and standardizes different message formats to ensure consistency.
The Scheduler Layer coordinates event timing and manages CDC use cases by interfacing with external data sources.
The Flow Control Layer adjusts task distribution based on subscriber capacity and handles state tracking.
The Delivery Layer routes messages while managing retries and health checks.
The Execution layer runs the actual tasks using lambda functions with built-in autoscaling and deployment safeguards. It automatically scales resources based on workload demands using Dropbox's Atlas infrastructure..
It reminds me of how Netflix too, when faced with scalability and tech debt challenges, did something which was fundamentally the same.
When their Video Encoding Service (VES) began to show signs of architectural strain, they also broke down a monolithic system into a microservice architecture with three distinct layers: Optimus (API), Plato (workflow), and Stratum (computing).
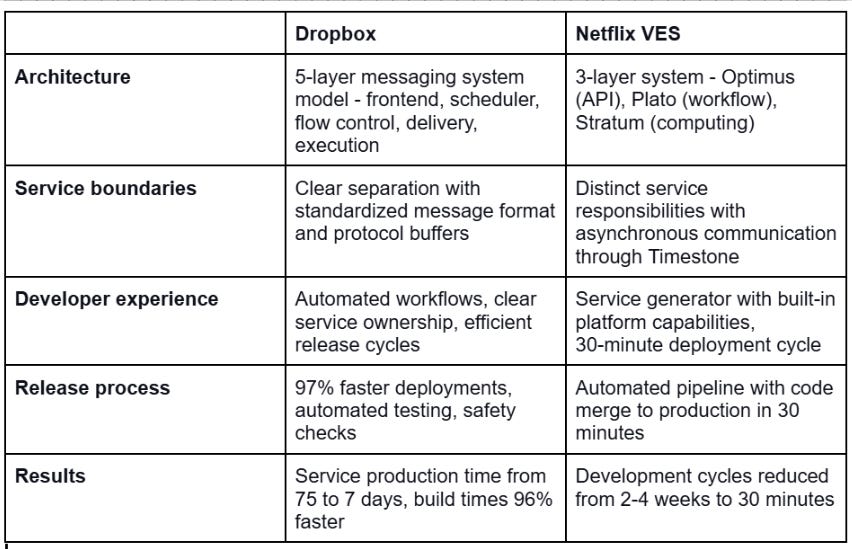
While their implementations differ, the core principles remain consistent: simplify development, automate processes, and maintain clear ownership.
What were the results?
Product engineers could now focus on innovation instead of dealing with complex infrastructure.
The manual processes that consumed their time were replaced with streamlined, automated workflows.
Moreover, the "Time to launch" for new product use cases was dramatically shortened, and platform owners' weekly " on-call time " dropped.
Now, this new infrastructure's reliability and self-healing abilities have resulted in fewer emergency interventions and more effective engineering.
Learn more about it here.
Here are some of the insightful editions you may have missed: