


How Airbnb Processes Unstructured Data from Millions of Users
An overview of how Airbnb extracts valuable insights from tons of unstructured text data generated by their users

Roses are red,
violets are blue,
let’s turn unstructured data
into something new!
Happy Valentine's Day, dear readers! ❤️️
I once worked on a BI platform that gathers data from over 2000 schools consisting of millions of students and thousands of teachers.
The goal was to build a specialized analytics platform to enable data-driven decision-making for District Administrators, Principals, and Board Leadership.
There wasn’t much uniformity in data points gathered from schools. The average school had 5+ data points, and on average, a district had over 50 systems.
We built a scalable ETL architecture using AWS Glue ETL over Apache Spark to bring all the data together in one data lake.

While most of the data gathered from sources was structured, some of it was unstructured as well. This was mostly remarks from teachers and parents.
We employed ML techniques to organize that data further to facilitate analytics.
The platform eventually allowed users to perform dynamic queries and apply advanced filters. Which in turn allowed them to generate powerful analytics.
Teams across the globe are converting unstructured data into structured data using NLP and ML strategies.
The applications of NLP are endless.
It can be used to convert handwritten notes from doctors into structured electronic health records.
It can be used to organize vast amounts of legal precedents from various sources into a structured repository to streamline legal research.
It can be used to extract sentiments from call center notes.
It can be used to convert unstructured financial transactions into structured categories for better analysis, and so on.
The implementations become more impressive when applied over a large scale.
Which is why I want to bring your attention to Airbnb’s use of NLP/ML to convert unstructured text data to insightful information for guests.
How Airbnb Processes Unstructured Data from Millions of Users
There are more than 7 million active listings on Airbnb. And it reported 393.7 million nights stayed in 2022 alone.
The text posted in listings and reviews shared by guests contains useful information for future guests. But only if it were organized.
And you can’t even think of manual processes at this scale.
Airbnb also doesn’t make its guests and hosts fill out lengthy forms to ensure a pleasant experience.
They developed a project called Listing Attribute Extraction Platform (LAEP) to extract listing attributes and identify their types to better structure the processed information.
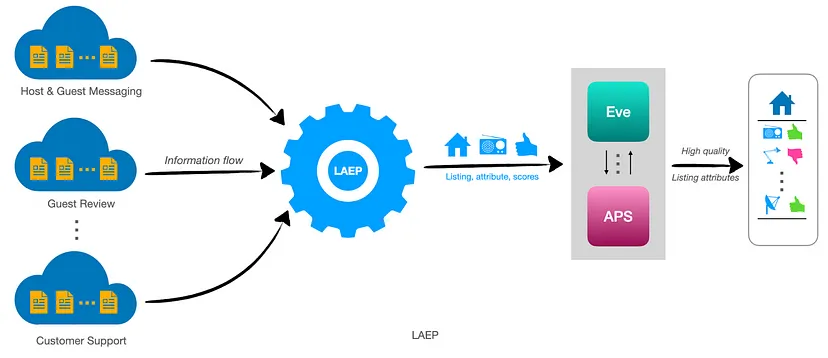
Source: The Airbnb tech blog
Here’s a brief on the three main components of LAEP and how Airbnb developed each of them
1. Named Entity Recognition (NER)
Airbnb built its own NER models to detect and classify specific phrases or entities in free text.
The model identifies entities like amenities, facilities, hospitality, location features, and structural details.
Text data undergoes preprocessing like lemmatization and tokenization before being fed into the NER model.
The output of the NER model is a list of detected named entities with their corresponding entity labels and span indices.
The team at Airbnb prepared a labeled dataset by sampling and lableling 30K example texts from various channels within the infrastructure.
They further defined entities relevant to the business. These were amenities, facilities, hospitality, location features, structural details, etc.
They then split the labeled dataset into training and testing datasets for model evaluation.

NER pipeline output example
Source: The Airbnb tech blog
2. Entity Mapping
Different people might use different terms for the same entity. This also includes the small fraction of typos. And the entity mapping component takes care of all the variations.
They had to map millions of phrases to hundreds of listings. While many phrases mapped to the attribute, some didn’t. They introduced confidence levels to establish rules for where mapping can’t be done.
Preprocessing techniques like lowercasing and lemmatization are applied to the listing attributes and detected phrases.
All standard listing attributes are mapped to the word-embedding space using a word2vec model fine-tuned with Airbnb's text data.
For a preprocessed detected phrase, the closest listing attribute is determined based on cosine similarity in the word-embedding space. The similarity score serves as the confidence score for the mapping.
3. Entity Scoring
After mapping a detected phrase to a standard listing attribute, they needed to infer the presence of the attribute in the listing.
The Airbnb team used a fine-tuned BERT model for text classification to determine the presence of attributes. It is trained on data from six different sources
The model analyzes the source data, including detected phrases and their local context, to infer the existence of attributes.
The entity scoring component outputs a discrete result indicating attribute presence (Yes, No, Unknown) along with a confidence score.

Source: The Airbnb tech blog
By applying these steps, Airbnb is able to extract structured information from unstructured text data, allowing for better understanding of listing attributes and enhancing the Airbnb experience for hosts and guests.
The output of this process is integrated into various applications, providing personalized services, recommending relevant attributes, and powering downstream tools for attribute prioritization and collection.